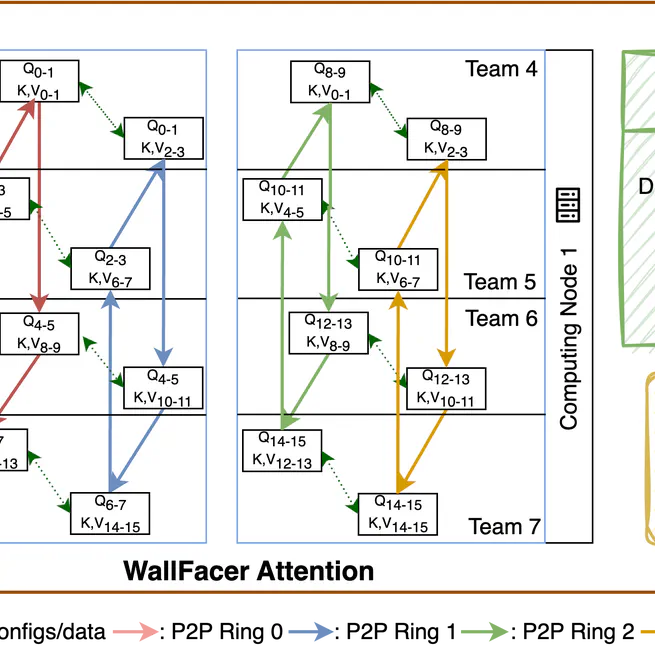
HelixPipe: Efficient Distributed Training of Long Sequence Transformers with Attention Parallel Pipeline Parallelism
PPoPP '26. A novel pipeline parallelism for long sequence transformer training.
Nov 11, 2025
WeiPipe: Weight Pipeline Parallelism for Communication-Effective Long-Context Large Model Training
PPoPP '25. A novel pipeline parallelism that communicate model weight rather than activation under long-sequence scenarios.
Nov 10, 2024
Concerto: Automatic Communication Optimization and Scheduling for Large-Scale Deep Learning
A compiler framework designed to address these challenges by automatically optimizing and scheduling communication
Oct 27, 2024
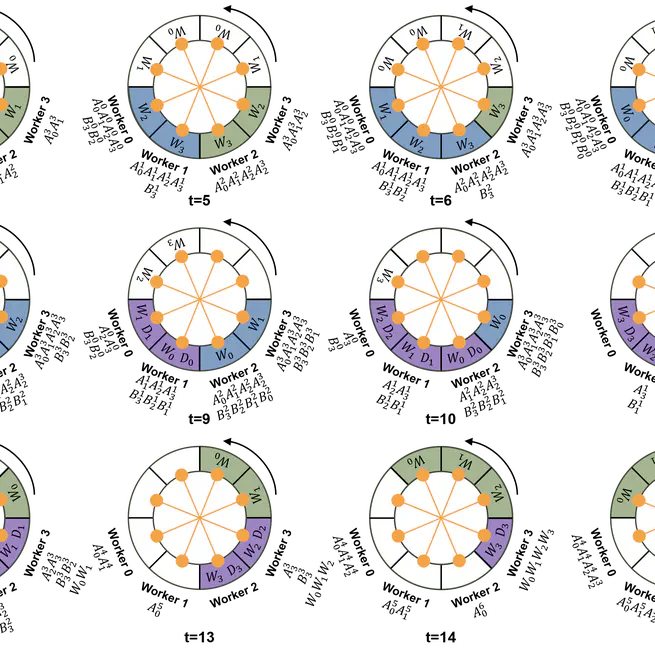
StarTrail: Concentric Ring Sequence Parallelism for Efficient Near-Infinite-Context Transformer Model Training
NeurIPS '25. Efficient Sequence Parallelism System for Transformer model training.
Jun 30, 2024
DSP: Dynamic Sequence Parallelism for Multi-Dimensional Transformers
Dynamic Sequence Parallelism for multi-dimensional transformers.
Jan 1, 2024
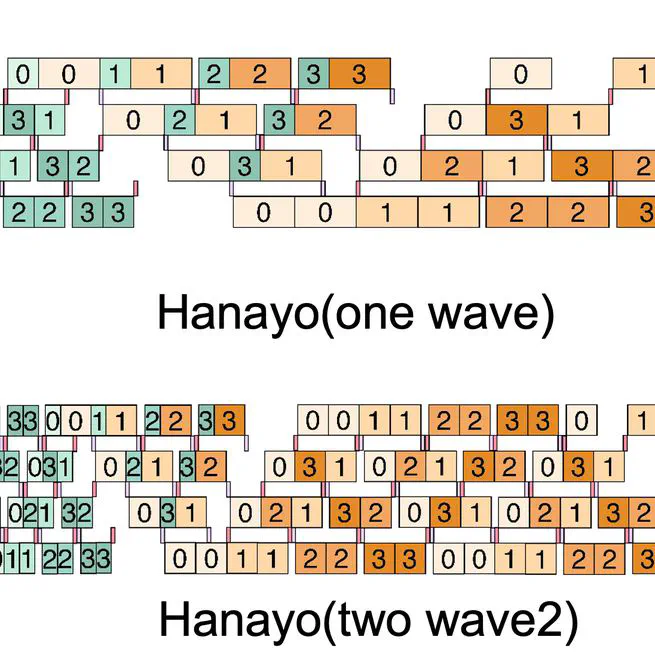
Hanayo: Harnessing Wave-like Pipeline Parallelism for Enhanced Large Model Training Efficiency
Accepted by SC '23. Efficient Pipeline Parallelism System for LLM.
Nov 11, 2023
ATP: Adaptive Tensor Parallelism for Foundation Models
Adaptive Tensor Parallelism for efficient foundation model training.
Jan 1, 2023
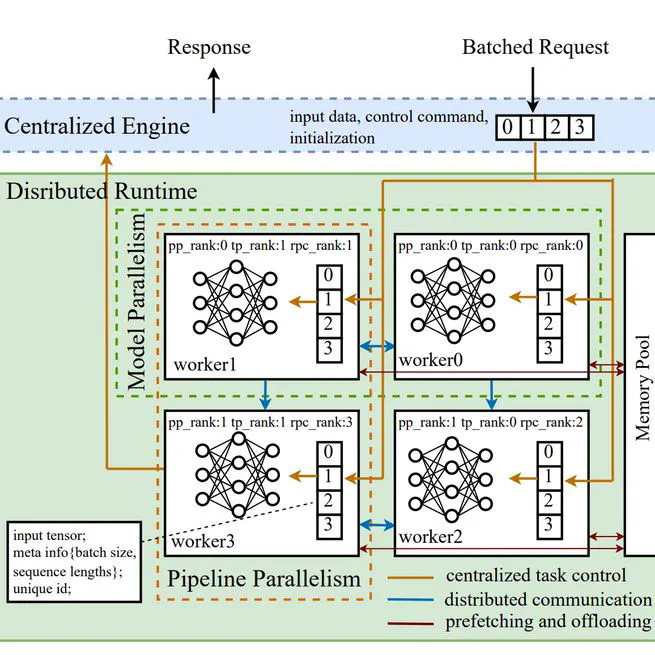
EnergonAI
A service framework for large-scale model inference, Energon-AI has the following characteristics: Parallelism for Large-scale Models: With tensor parallel operations, pipeline parallel wrapper, distributed checkpoint loading, and customized CUDA kernel, EnergonAI can enable efficient parallel inference for larges-scale models. Pre-built large models: There are pre-built implementation for popular models, such as OPT. It supports the cache technique for the generation task and distributed parameter loading. Engine encapsulation: There has an abstraction layer called engine. It encapsulates the single instance multiple devices (SIMD) execution with the remote procedure call, making it acts as the single instance single device (SISD) execution. An online service system: Based on FastAPI, users can launch a web service of the distributed infernce quickly. The online service makes special optimizations for the generation task. It adopts both left padding and bucket batching techniques for improving the efficiency. For models trained by Colossal-AI, they can be easily transferred to Energon-AI. For single-device models, they require manual coding works to introduce tensor parallelism and pipeline parallelism.
Feb 1, 2022