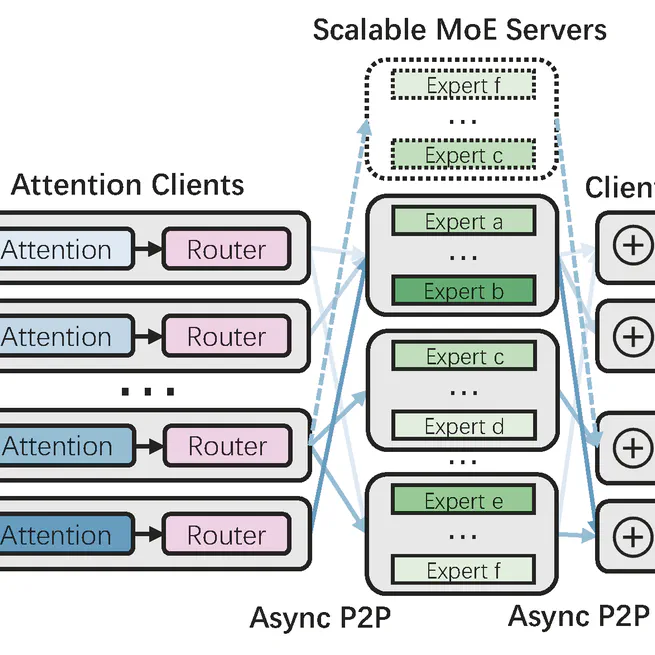
Expert-as-a-Service: Towards Efficient, Scalable, and Robust Large-scale MoE Serving
EaaS, a novel serving system to enable efficient, scalable, and robust MoE deployment.
Sep 22, 2025
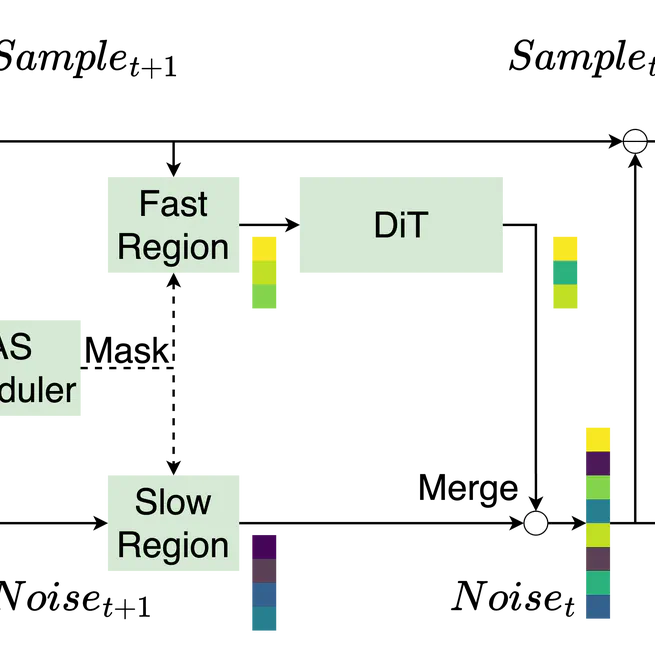
Region-Adaptive Sampling for Diffusion Transformers
CVPR '26. RAS, the first diffusion sampling strategy that allows for regional variability in sampling ratios, achieving up to 2x+ speedup!
Feb 14, 2025
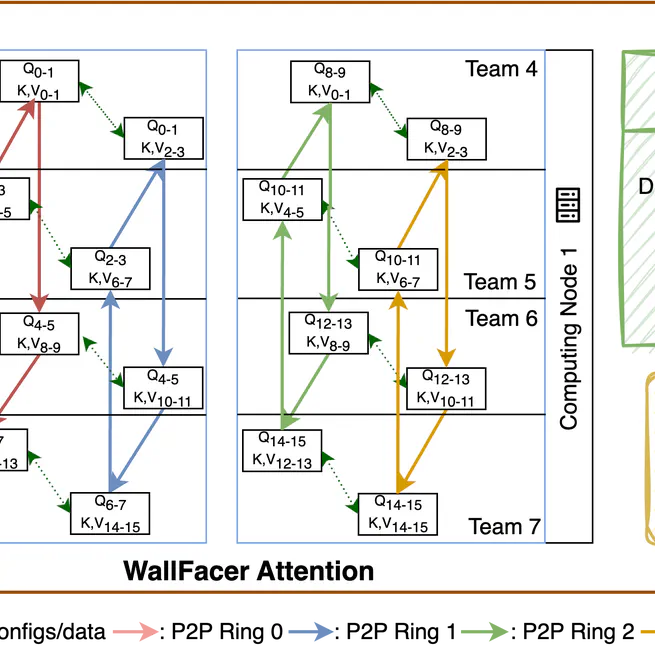
StarTrail: Concentric Ring Sequence Parallelism for Efficient Near-Infinite-Context Transformer Model Training
NeurIPS '25. Efficient Sequence Parallelism System for Transformer model training.
Jun 30, 2024
AutoChunk: Automated Activation Chunk for Memory-Efficient Long Sequence Inference
Memory-efficient long sequence inference through automated activation chunking.
May 7, 2024
ATP: Adaptive Tensor Parallelism for Foundation Models
Adaptive Tensor Parallelism for efficient foundation model training.
Jan 1, 2023
EnergonAI: An Inference System for 10-100 Billion Parameter Transformer Models
An inference system designed for handling 10-100 billion parameter transformer models efficiently.
Jan 1, 2022