WeiPipe: Weight Pipeline Parallelism for Communication-Effective Long-Context Large Model Training
Nov 10, 2024· ,,,,·
0 min read
,,,,·
0 min read
Junfeng Lin*
Ziming Liu*
Yang You
Jun Wang
Weihao Zhang
Rong Zhao
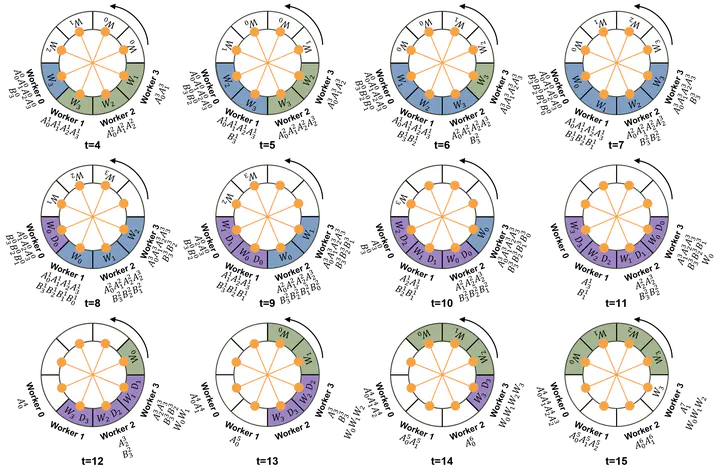 WeiPipe-Zero-Bubble
WeiPipe-Zero-BubbleAbstract
Training large language models (LLMs) has become increasingly expensive due to the rapid expansion in model size. Pipeline Parallelism is a widely used distributed training technique. However, as LLMs with larger context become prevalent and memory optimization techniques advance, traditional PP methods encounter greater communication challenges due to the increased size activations and gradients of activations. To address this issue, we introduce weight-pipeline parallelism (WeiPipe) that transitions from an activation-passing pipeline to a weight-passing pipeline. WeiPipe reduces communication costs and achieves more balanced utilization by transmitting only weights and their gradients between workers in a pipelined manner. WeiPipe does not rely on collective communication primitives, thus ensuring scalability. We present four variations of WeiPipe parallelism, including WeiPipe-Interleave, which emphasizes communication efficiency, and WeiPipe-Zero-Bubble, discussing the potential for minimal bubble ratios. Our implementation of WeiPipe-Interleave, performed on up to 32 GPUs and tested in large-context LLM training, demonstrates up to a 30.9% improvement in throughput with NVLink connections and an 82% improvement with PCIe and IB connections compared to state-of-the-art pipeline parallelism. Additionally, WeiPipe shows greater strong scalability compared to Fully Sharded Data Parallelism.
Type
Publication
PPoPP 2025