StarTrail: Concentric Ring Sequence Parallelism for Efficient Near-Infinite-Context Transformer Model Training
Jun 30, 2024· ,,,,,,,·
0 min read
,,,,,,,·
0 min read
Ziming Liu
Shaoyu Wang
Shenggan Cheng
Zhongkai Zhao
Kai Wang
Xuanlei Zhao
James Demmel
Yang You
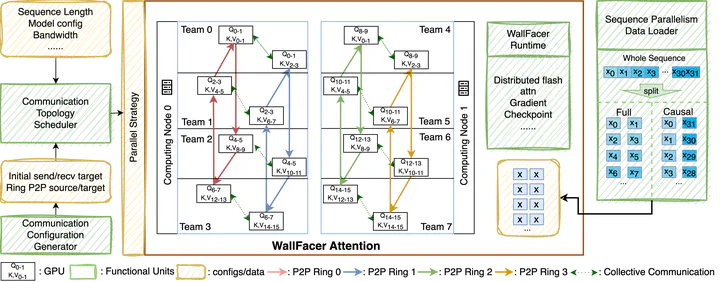 StarTrail Attention Block
StarTrail Attention BlockAbstract
Training Transformer models on long sequences in a distributed setting poses significant challenges in terms of efficiency and scalability. Current methods are either constrained by the number of attention heads or excessive communication overheads. To address this problem, we propose StarTrail, a multi-dimensional concentric distributed training system for long sequences, fostering an efficient communication paradigm and providing additional tuning flexibility for communication arrangements. Specifically, StarTrail introduces an extra parallel dimension and divides the peer-to-peer communication into sub-rings to substantially reduce communication volume and avoid bandwidth bottlenecks. Through comprehensive experiments across diverse hardware environments and on both Natural Language Processing (NLP) and Computer Vision (CV) tasks, we demonstrate that our approach significantly surpasses state-of-the-art methods that support Long sequence lengths, achieving performance improvements of up to 77.12% on GPT-style models and up to 114.33% on DiT (Diffusion Transformer) models without affecting the computations results.
Type
Publication
NeurIPS 2025